on
Managing Machine Learning Products
Developing systems with machine learning components involves more uncertainty and risk than developing “traditional” (i.e., deterministic) software systems. Therefore, developing products that incorporate machine learning requires specific management practices. Are you familiar with these practices? Is your organization overlooking any practices that are important to your context?
I had the opportunity to co-author an article that identifies such practices. This is a very useful text for software engineers, data engineers, data scientists, but mainly for managers involved with products that incorporate machine learning. In this post, we present some reflections retrieved from the article, entitled Practices for Managing Machine Learning Products: a Multivocal Literature Review and published in the journal IEEE Transactions on Engineering Management.
The considerations presented here are organized around the phases of the development process of systems incorporating machine learning (Figure 1).
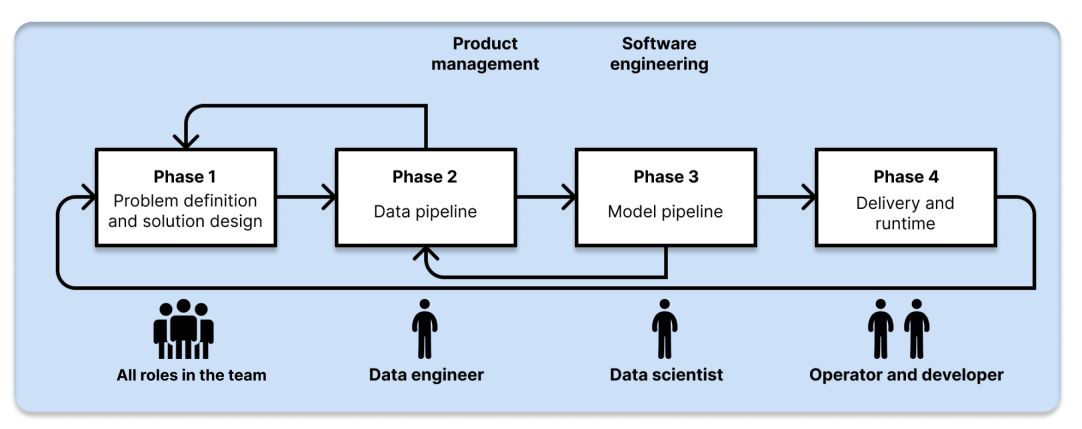
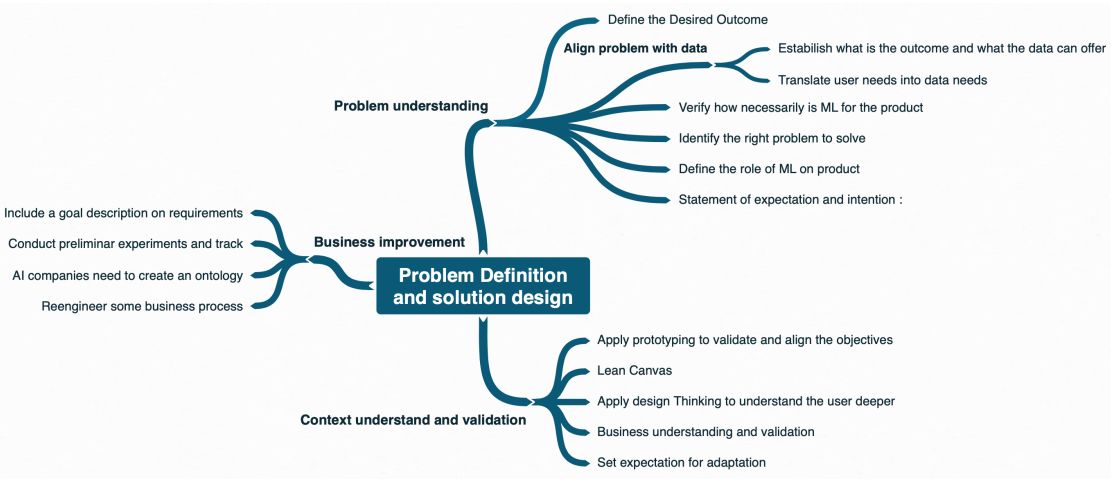
Problem definition and solution design
Systems that use machine learning (ML) have probabilistic results, rather than deterministic ones like traditional applications. Therefore, the risks are greater. To mitigate these risks, first of all, it is necessary to be sure that the use of ML is really relevant to the context.
In particular, managers should establish from the beginning a clear objective for the module using ML in the system. This will help data scientists in later stages, such as when making decisions about algorithm optimizations.
For this to be possible, managers must understand the basics of ML algorithms to identify the types of problems that data can solve (e.g., prediction, recommendation, anomaly detection).
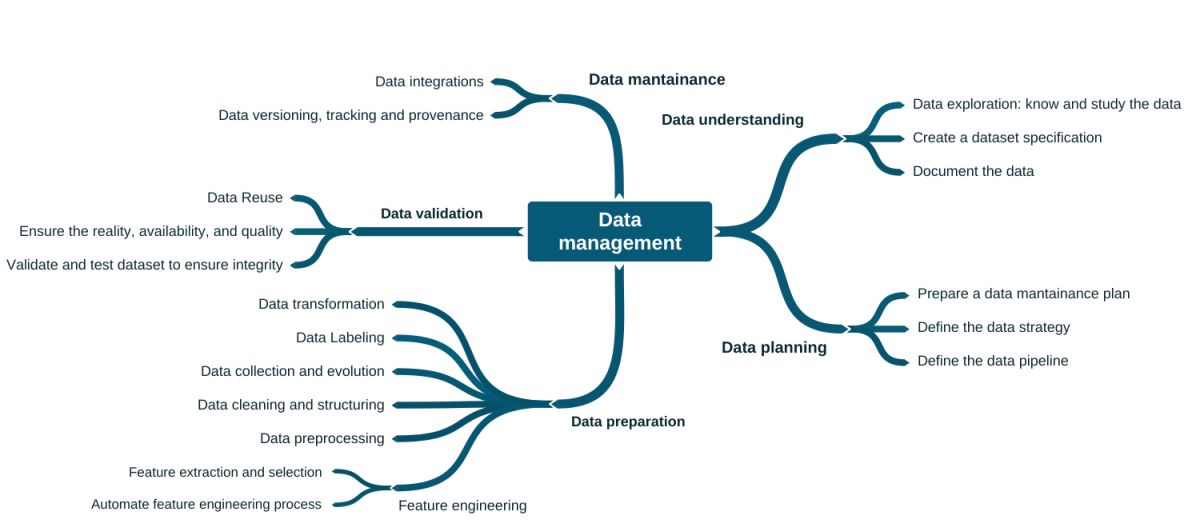
Data management
Software engineers are already familiar with the application deployment pipeline [1]. But for systems using machine learning (ML), we also have data and model pipelines. Figure 3 lists several practices related to the data pipeline. These practices are about planning, understanding data, preparing data, maintaining data, and validating data. These disciplines are typically the domain of data engineers and data scientists.
However, the substantial volume of data brings new challenges for data engineering, since personal computers cannot handle the processing of this volume. We then have adaptations in the data science workflow, with experiments in cloud environments, potentially applied to different environments with different configurations. Therefore, automation becomes crucial. Other automations may be necessary, such as data pipeline and data preprocessing customization. Consequently, data engineers also have several complex and relevant assignments.
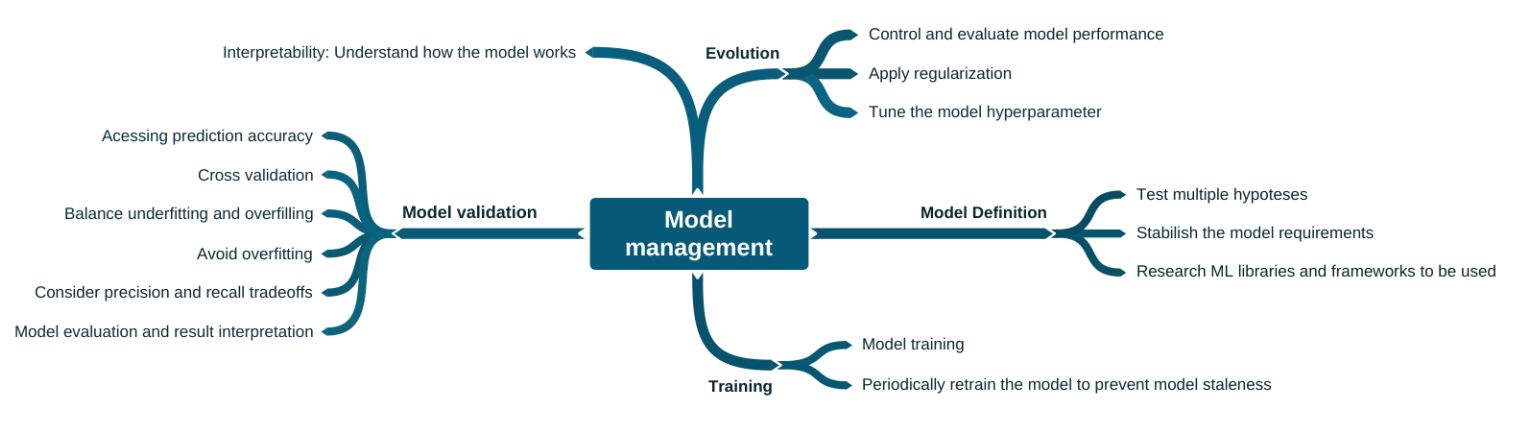
Model management
Figure 4 lists several practices related to the (machine learning) model pipeline. These are the practices typically conducted by data scientists, such as training, validation, and interpretability.
However, in the context of product, there are some differences in relation to what is usually done for a POC or experiment. These differences are the long-term activities, which concern the evolution of the model. Example: periodically retraining the model to prevent it from becoming outdated. Furthermore, it is pertinent that managers have knowledge about learning models and these related practices to identify opportunities.
Extra-article note: a recent concern about model management is the explainability of the model [2]. Example: if a loan was denied due to an ML decision, how one can justify such a decision to the affected person?
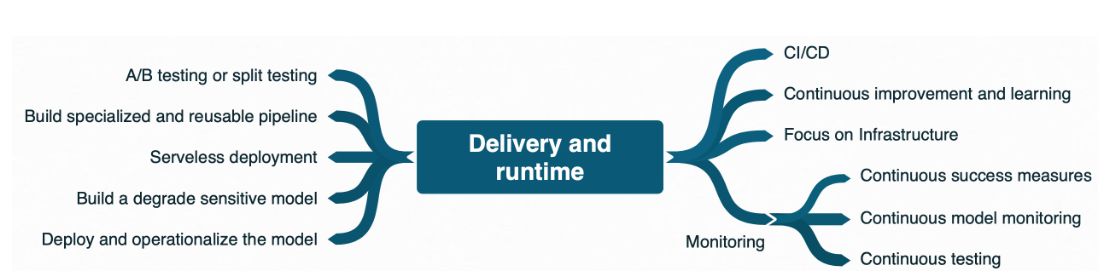
Delivery and runtime management
There are differences in the management of products that use machine learning (ML) compared to so-called deterministic software systems. In this sense, the delivery and runtime monitoring of ML products are challenging. Figure 5 lists several practices related to this stage of the ML product lifecycle.
Production data must be consistent with training data, while new data must be collected to keep the product working properly. Thus, continuous training is important, since ML models can decay in more ways than conventional systems. Production data is mutable; therefore, continuous success monitoring is necessary to verify that the system still operates properly, despite success in the laboratory or past success in production. User feedback is even more essential to improve the product, since ML systems are more likely to exhibit unexpected behaviors in production.
Product management
Product management practices (Figure 6) should be considered not only by managers, but also by engineers and data scientists. These practices end up being relevant even for model validation. For example, one of the most cited practices is user feedback-driven model improvement, which consists of promoting experiments and defining metrics to evaluate ML products with beta users, in addition to obtaining implicit feedback from end users. 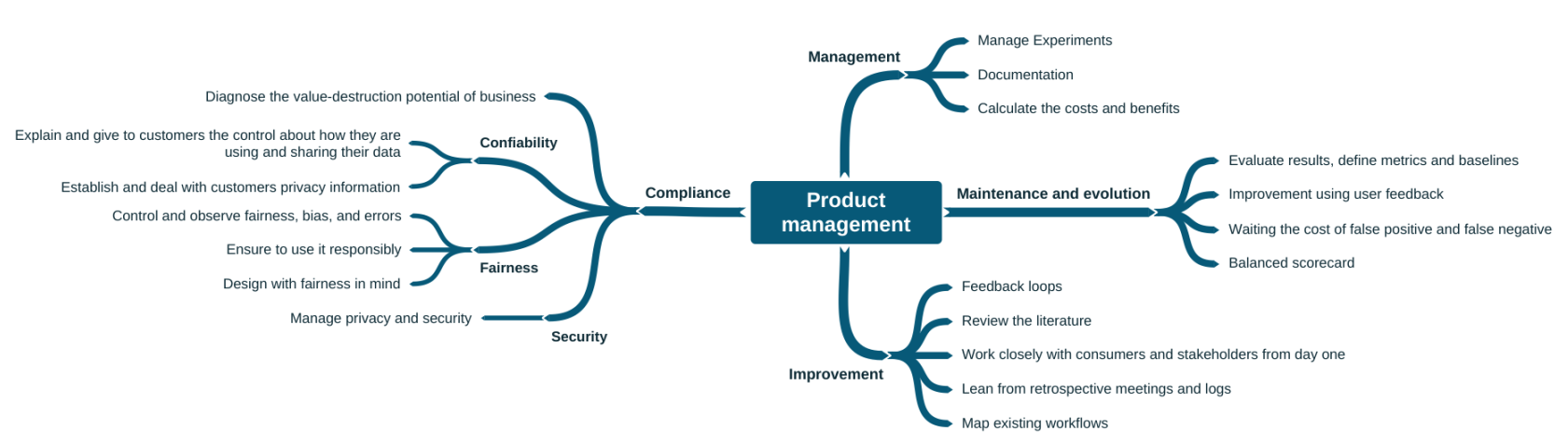
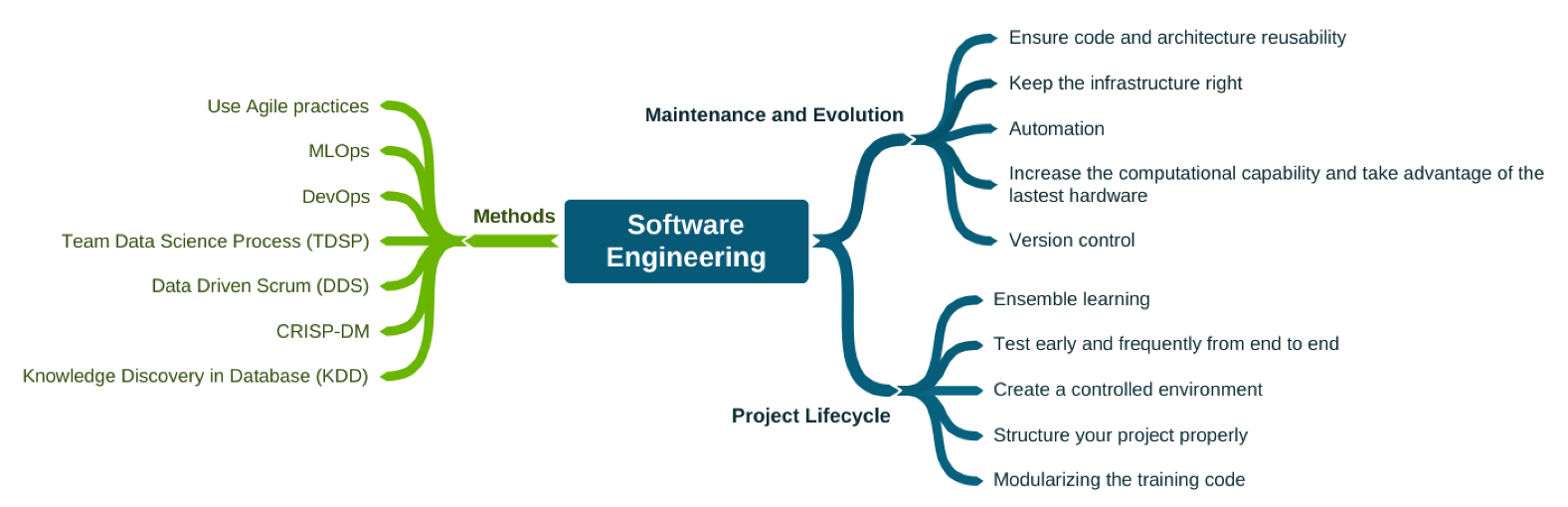
Software engineering
Figure 7 lists software engineering methods and practices essential for developing products that incorporate machine learning. Modularization, one of the major themes of software engineering, for example, applies to model isolation, including when using ensemble learning (combining multiple models to achieve a better result). DevOps and MLOps, other examples, will help data engineers ensure the reproducibility of ML experiments. MLOps also encompasses collaboration and communication practices between data scientists and operations professionals. Thinking from a development process perspective, there is also the prescription of iterative (agile) processes specific to the data science context.
Publication
Isaque Alves, Leonardo Leite, Paulo Meirelles, Fabio Kon, Carla Rocha. Practices for Managing Machine Learning Products: A Multivocal Literature Review. IEEE Transactions on Engineering Management. Vol. 71, 2024.
Abstract. Machine Learning (ML) has grown in popularity in the software industry due to its ability to solve complex problems. Developing ML Systems involves more uncertainty and risk because it requires identifying a business opportunity and managing the source code, data, and trained model. Our research aims to identify the existing practices used in the industry for building ML applications. The goal is to comprehend the orga- nizational complexity of adopting ML Systems. We conducted a Multivocal Literature Review (MLR) and used Grounded Theory (GT) to build a taxonomy with the practices applied to the ML System lifecycle from the industry and academic perspectives. We selected 41 posts from grey literature and 37 papers from scientific repositories. Following a systematic GT protocol, we mapped 91 practices, grouped in 6 core categories related to designing, developing, testing, and deploying ML Systems. The results can help organizations identify the gaps in their current ML processes and practices, and provide a roadmap for improving and optimizing their ML systems. The comprehensive taxonomy of practices developed in this research serves as a valuable tool for managers, practitioners, and researchers in the ML field, providing a clear and organized understanding of the complexity of managing ML systems.
References
[1] Jez Humble and David Farley. Continuous Delivery: reliable software releases through build, test, and deployment automation. 2010.
[2] Aline Macohin. Inteligência Artificial na Administração Pública Brasileira: uma abordagem transparente e explicável. 2023.