em
Gerenciando produtos com componentes de aprendizado de máquina (machine learning)
Desenvolver sistemas com componentes de aprendizado de máquina envolve mais incerteza e riscos do que desenvolver sistemas de software “tradicionais” (i.e., determinísticos). Portanto, o desenvolvimento de produtos embutindo aprendizado de máquina requer práticas específicas de gerenciamento. Será que você conhece essas práticas? Será que sua organização está deixando de lado alguma prática importante para o seu contexto?
Tive a oportunidade de coautorar um artigo que identifica tais práticas. Esse é um texto muito útil a engenheiros de software, engenheiros de dados, cientistas de dados, mas principalmente a gestores envolvidos com produtos embutindo aprendizado de máquina. Neste post, apresentamos alguma reflexões trazidas do artigo, intitulado Practices for Managing Machine Learning Products: a Multivocal Literature Review e publicado no periódico IEEE Transactions on Engineering Management, do qual participei com grande elenco: Isaque Alves, Carla Rocha, Paulo Meirelles e Fabio Kon.
As ponderações aqui trazidas são organizadas em torno das fases do processo de desenvolvimento de sistemas embarcando aprendizado de máquina (Figura 1).
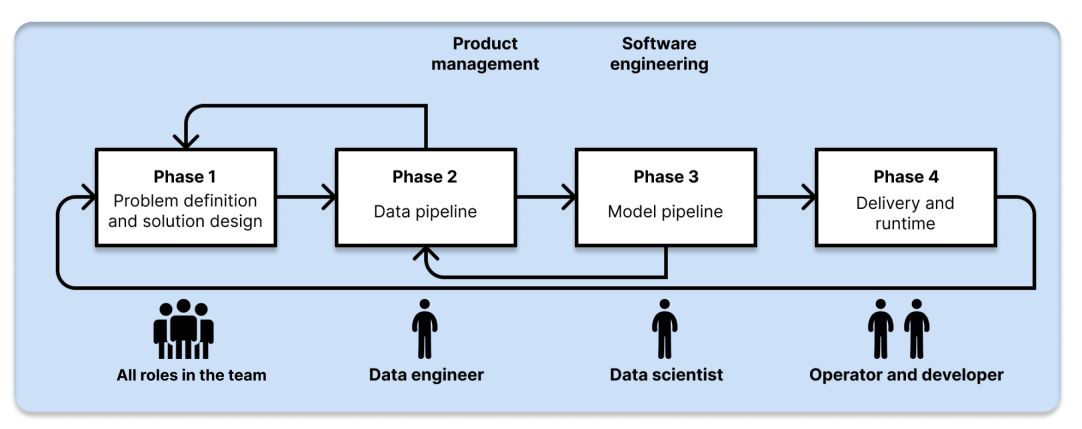
Definição do problema e desenho da solução
Sistemas que utilizam aprendizado de máquina (ML - machine learning) possuem resultados probabilísticos, e não determinísticos como as aplicações tradicionais. Portanto os riscos são maiores. Para mitigar esses riscos, em primeiro lugar, é preciso estar seguro de que o uso de ML é realmente pertinente ao contexto.
Em particular, gerentes devem estabelecer desde o início um objetivo claro para o módulo usando ML no sistema. Isso ajudará os cientistas de dados em etapas posteriores, como por exemplo ao tomar decisões sobre otimizações do algoritmo.
Para que isso seja possível, gerentes devem compreender o básico dos algoritmos de ML para identificar os tipos de problemas que os dados podem resolver (ex: predição, recomendação, detecção de anomalia).
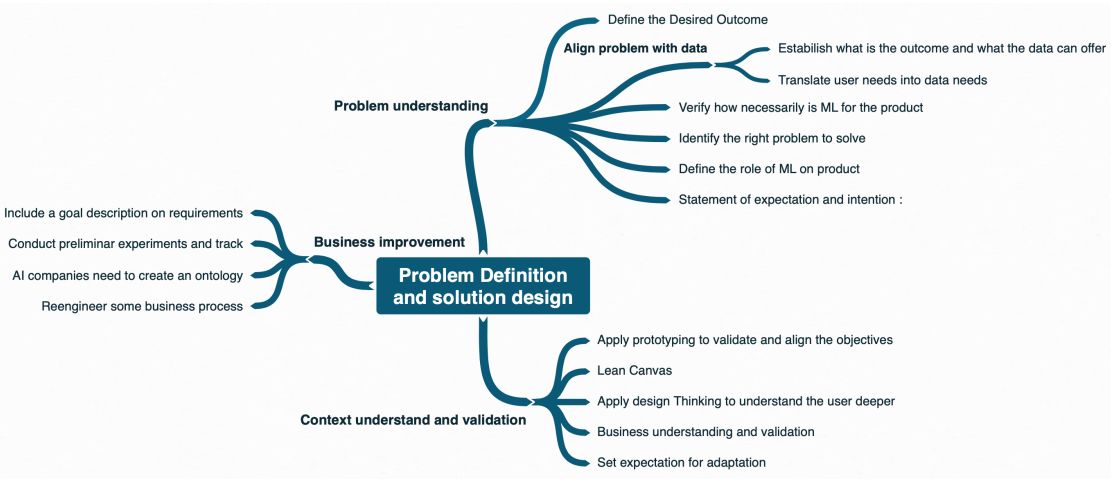
Gerenciamento dos dados
Engenheiros de software já estão bem acostumados com o pipeline de implantação de aplicações [1]. Mas para sistemas usando aprendizado de máquina, temos também os pipelines de dados e do modelo. A Figura 3 lista diversas práticas relacionadas ao pipeline de dados. Essas práticas são sobre planejamento, entendimento dos dados, preparação dos dados, manutenção dos dados e validação dos dados. Essas são disciplinas normalmente de domínio de engenheiros e cientistas de dados.
Contudo, o volume substancial de dados traz novos desafios para engenharia de dados, uma vez que os computadores pessoais não suportam o processamento deste volume. Temos então adaptações no fluxo de trabalho da ciência de dados, com experimentos em ambientes de nuvem, potencialmente aplicados a diferentes ambientes com diferentes configurações. Portanto, a automação torna-se crucial. Outras automações podem ser necessárias, como pipeline de dados e personalização de pré-processamento de dados. Consequentemente, engenheiros de dados também tem diversas atribuições complexas e relevantes.
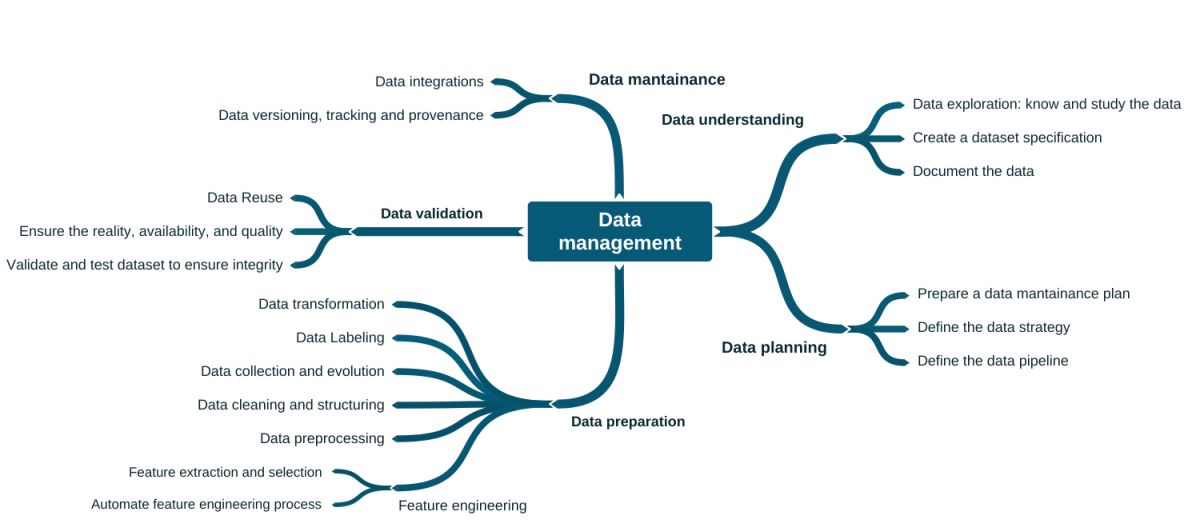
Gerenciamento do modelo
A Figura 4 lista diversas práticas relacionadas ao pipeline de modelo (de aprendizado de máquina). Essas são as práticas tipicamente conduzidas por cientistas de dados, como treino, validação e interpretabilidade.
Contudo, no contexto de produto, há alguns diferenciais em relação ao que se costuma fazer para uma POC ou experimento. Esses diferenciais são as atividades de longo prazo, que dizem respeito à evolução do modelo. Exemplo: retreinar periodicamente o modelo para evitar que se torne defasado. No mais, é pertinente que gestores tenham conhecimentos sobre os modelos de aprendizado e essas práticas relacionadas para a identificação oportunidades.
Observação extra-artigo: uma preocupação em voga mais recentemente sobre o gerenciamento do modelo é sobre a explicabilidade desse modelo [2]. Exemplo: se determinado empréstimo foi negado por uma decisão de ML, como justificar à pessoa afetada tal negativa?
Gerenciamento de entrega e do ambiente de execução
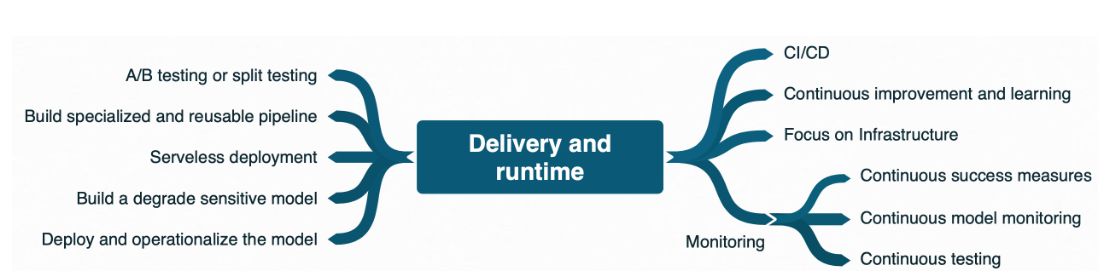
Existem diferenças na gerência de produtos que utilizam aprendizado de máquina em relação a sistemas de software ditos determinísticos. Nesse sentido, a entrega e o monitoramento em tempo de execução de produtos de ML são desafiadores. A Figura 5 lista diversas práticas relacionadas à essa etapa do ciclo de vida de produtos de ML.
Os dados de produção devem ser consistentes com dados de treinamento, enquanto novos dados devem ser coletados para manter o correto funcionamento do produto. Assim, o treinamento contínuo é importante, pois os modelos de ML podem decair de mais maneiras do que sistemas convencionais. Os dados de produção são mutáveis; portanto, o monitoramento contínuo de sucesso é necessário para verificar se o sistema ainda opera adequadamente, a despeito de sucesso em laboratório ou de sucesso passado em produção. O feedback de usuários é ainda mais essencial para incrementar o produto, uma vez que os sistemas de ML são mais propensos a apresentar comportamentos inesperados em produção.
Gerenciamento de produto
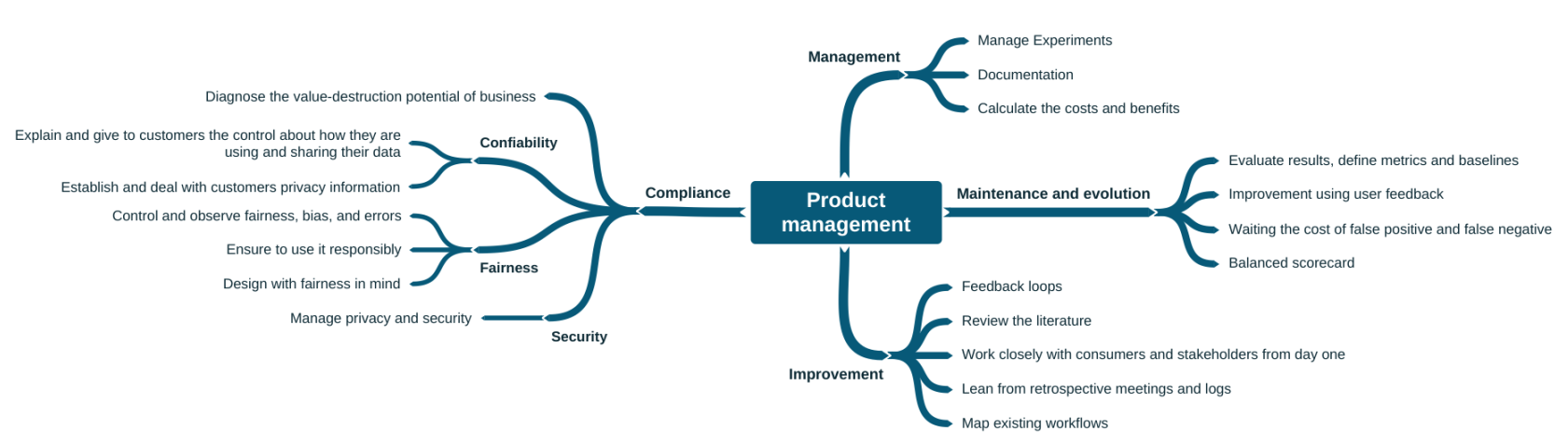
As práticas de gerenciamento de produto (Figura 6) devem ser consideradas não só por gestores, mas também por engenheiros e cientistas de dados. Essas práticas acabam sendo relevantes inclusive para a validação do modelo. Por exemplo, uma das práticas mais citadas é a melhoria do modelo baseada em feedback do usuário, que consiste em promover experimentos e definir métricas para avaliar produtos de ML com usuários beta, além da obtenção de feedback implícito dos usuários finais.
Engenharia de software
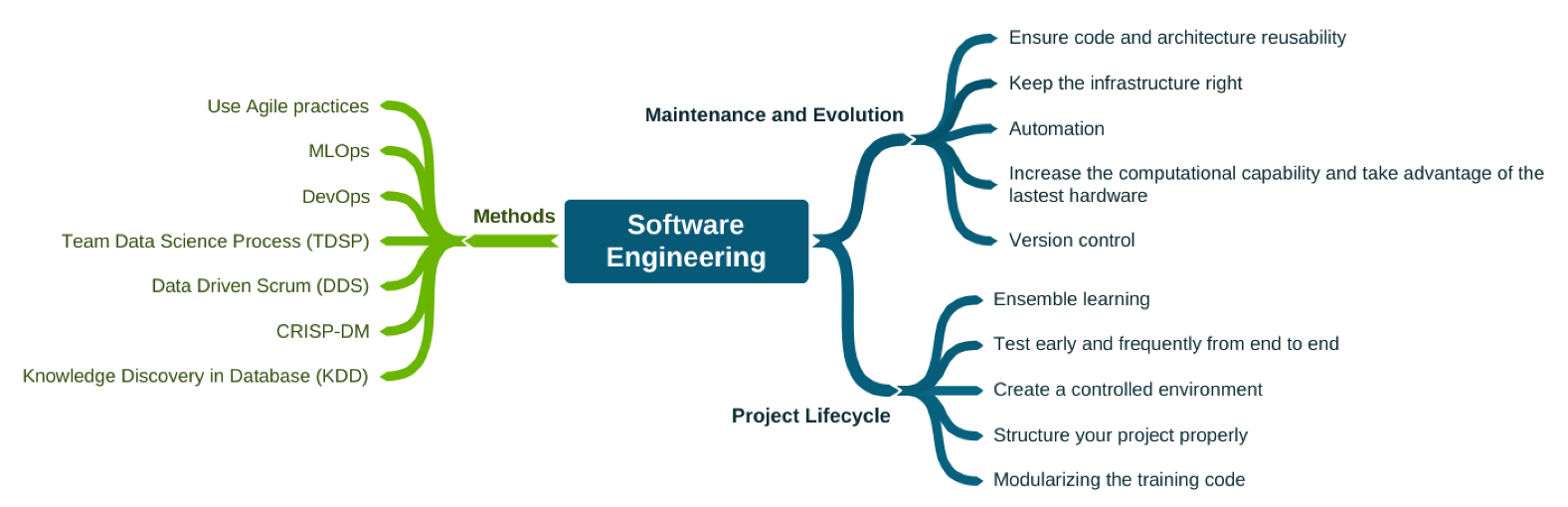
A Figura 7 lista métodos e práticas da engenharia de software essenciais para o desenvolvimento de produtos embarcando aprendizado de máquina. Modularização, um dos grandes temas da engenharia de software, por exemplo, se aplica para o isolamento de modelos, inclusive quando da utilização de aprendizagem em conjunto (combinação de múltiplos modelo para se atingir um melhor resultado). Já DevOps e MLOps, outros exemplos, ajudarão engenheiros de dados a garantir a reprodutibilidade dos experimentos de ML. O MLOps também abarca práticas de colaboração e comunicação entre cientistas de dados e profissionais de operações. Pensando numa perspectiva de processo de desenvolvimento, há também a prescrição de processos iterativos (ágeis) específicos para o contexto de ciência de dados.
Publicação
Isaque Alves, Leonardo Leite, Paulo Meirelles, Fabio Kon, Carla Rocha. Practices for Managing Machine Learning Products: A Multivocal Literature Review. IEEE Transactions on Engineering Management. Vol. 71, 2024.
Abstract. Machine Learning (ML) has grown in popularity in the software industry due to its ability to solve complex problems. Developing ML Systems involves more uncertainty and risk because it requires identifying a business opportunity and managing the source code, data, and trained model. Our research aims to identify the existing practices used in the industry for building ML applications. The goal is to comprehend the orga- nizational complexity of adopting ML Systems. We conducted a Multivocal Literature Review (MLR) and used Grounded Theory (GT) to build a taxonomy with the practices applied to the ML System lifecycle from the industry and academic perspectives. We selected 41 posts from grey literature and 37 papers from scientific repositories. Following a systematic GT protocol, we mapped 91 practices, grouped in 6 core categories related to designing, developing, testing, and deploying ML Systems. The results can help organizations identify the gaps in their current ML processes and practices, and provide a roadmap for improving and optimizing their ML systems. The comprehensive taxonomy of practices developed in this research serves as a valuable tool for managers, practitioners, and researchers in the ML field, providing a clear and organized understanding of the complexity of managing ML systems.
Referências
[1] Jez Humble and David Farley. Continuous Delivery: reliable software releases through build, test, and deployment automation. 2010.
[2] Aline Macohin. Inteligência Artificial na Administração Pública Brasileira: uma abordagem transparente e explicável. 2023.