em
Sentry para Spring Boot, um tutorial
O Sentry é uma plataforma de monitoramento de desempenho e rastreamento de erros que ajuda desenvolvedores a identificar, diagnosticar e corrigir falhas em suas aplicações. Sua principal funcionalidade é a exibição de erros da aplicação de forma agregada, de tal sorte que a equipe responsável pelo sistema consegue ter uma ideia dos erros que mais afetam o sistema, assim como da distribuição desses erros ao longo do tempo.
![]()
Mas o Sentry possui também uma funcionalidade de rastro distribuído (tracing), o que rivaliza um tanto com outras soluções, como o Jaeger, o OpenZipkin e o Grafana Tempo. Para que posteriormente eu tivesse condições de estabelecer uma comparação entre essas soluções, principalmente no que se refere ao suporte para análise de rastro distribuído, resolvi primeiro entender o Sentry com mais profundidade, conhecendo todos os potenciais benefícios que ele pode trazer.
Uma motivação para publicar esse tutorial foi a escassez de fontes sobre o Sentry, inclusive de bons vídeos no Youtube. Além disso, percebi algumas omissões e imprecisões relevantes na documentação oficial do Sentry.
O que não vamos cobrir aqui: conceitos básicos sobre rastro distribuído (tracing). Para isso, você pode conferir esse outro post nosso sobre rastro distribuído.
Então vamos lá!
Cenário
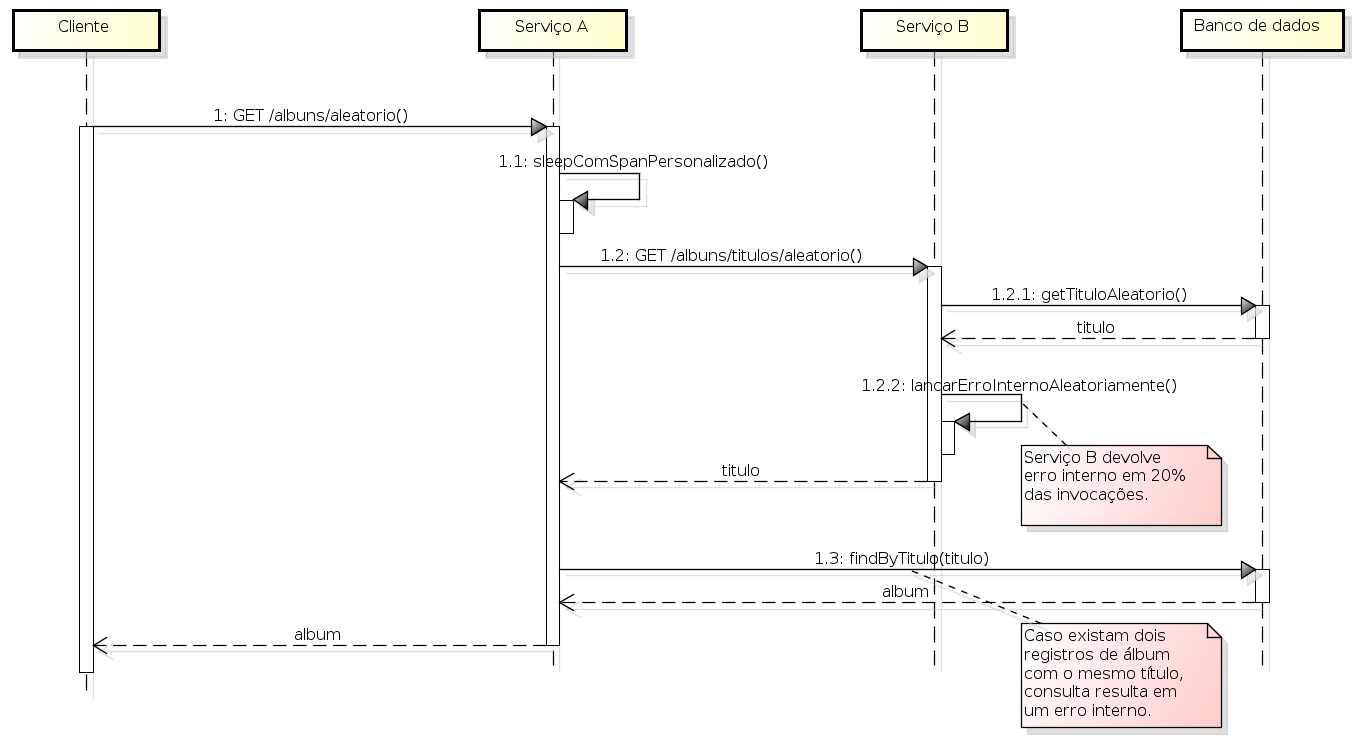
Para uma boa análise das funcionalidades do Sentry, principalmente em relação ao rastro distribuído, é preciso montar um cenário conveniente para tal análise, envolvendo pelo menos dois serviços. Montamos então um cenário com os serviços A e B seguindo o segunte fluxo:
- Quando invocado, o serviço A primeiramente faz uma pausa de 1 segundo, simulando assim algum processamento mais demorado.
- Serviço A chama serviço B para obter um título de álbum aleatório.
- Serviço B obtém o título aleatório do banco de dados e o devolve ao serviço A.
- Serviço A obtém o álbum completo, procurando o álbum pelo título no banco de dados.
- Alguns álbuns estão duplicados na tabela. Se Serviço B retornar um título de um desses álbuns duplicados, haverá um erro interno no serviço A (o que é interessante para monitoração).
- Às vezes o serviço B também retorna um erro interno de forma aleatória (20% das vezes que é chamado). Ao receber um erro interno de B, o serviço A também responde com um erro interno.
A descrição acima está abaixo representada como um diagrama de sequência:
O código-fonte desses serviços, já com a instrumentação do Sentry, se encontra disponível em https://gitlab.com/leo-observability-labs/sentry-lab.
Obs: a versão utilizada do Spring Boot é a 3.4.1.
Configuração inicial
Primeiramente, criamos dois projetos Sentry em https://sentry.io: o projeto servico-a e o projeto servico-b. Ao se criar um projeto, o Sentry exibe uma página de como realizar as configurações básicas, que são as que seguem.
Em build.gradle:
plugins {
id "io.sentry.jvm.gradle" version "4.14.1"
}
sentry {
includeSourceContext = true
org = "leite-oe"
projectName = "servico-a"
authToken = System.getenv("SENTRY_AUTH_TOKEN")
}
No application.properties:
sentry.dsn=https://ac25fa38da889012dc40717e0e32b071@o4508698572029952.ingest.us.sentry.io/450875676046XYZX
sentry.traces-sample-rate=1.0
Colocar o Sentry.captureException(e) no exception handler:
@ControllerAdvice
@Log4j2
public class ServiceAExceptionHandler {
@ExceptionHandler(RuntimeException.class)
public ResponseEntity<MensagemDeErroInterno> runtimeException(RuntimeException e, HttpServletRequest request) {
log.error("Erro inesperado: " + e.getMessage(), e);
Sentry.captureException(e);
MensagemDeErroInterno msg = new MensagemDeErroInterno();
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR.value()).body(msg);
}
}
Para subir o serviço, também ciamos um script (onde o valor de SENTRY_AUTH_TOKEN é fornecido pela página de configuração inicial do projeto):
set -e # interrompe script se qualquer comando falhar
clear
export SENTRY_AUTH_TOKEN=sntrys_eyJpYXQiOjE3Mzg2MDgwOTYuNDkzNDMsInVybCI6Imh0dHBzOi8vc2VudHJ5LmlvIXYZX
./gradlew clean build
java -jar build/libs/serviceA-0.0.1-SNAPSHOT.jar
Os passos acimas foram aplicados tanto para o serviço A, quanto para o serviço B.
Invocação entre serviços
Para que a visão de rastro distribuído funcione adequadamente é preciso um cuidado. Ao utilizar o RestTemplate para invocar outro serviço (no caso A chamando B), é preciso que o objeto restTemplate tenha sido criado a partir de um RestTemplateBuilder fornecido pelo framework. Em outras palavras, não instanciar o restTemplate com new! Para isso, criamos então a classe AppConfig como uma fábrica de restTemplate:
@Configuration
public class AppConfig {
@Bean
RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
}
E no local de uso do restTemplate é só injetar o mesmo:
@RestController
@Log4j2
public class ServiceAController {
@Autowired
private RestTemplate restTemplate; // e aí, só usar
// ....
private String acessarOutroServicoParaPegarUmTituloAleatorio() {
String url = "http://localhost:8092/service-b/albuns/titulos/aleatorio";
try {
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
return response.getBody();
} catch (HttpStatusCodeException e) {
throw new IllegalStateException("Failed to get random album title from service B");
}
}
}
Dessa forma, a propagação do trace ID gerado pela instrumentação do Sentry será realizada automaticamente.
Span personalizado
Para destacar de forma personalizada um trecho do código no trace do Sentry como um span, podemos fazer o segunite:
var activeTransaction = Sentry.getSpan();
var span = activeTransaction.startChild("Dormindo", "app.logic");
try {
Thread.sleep(1000);
span.finish(SpanStatus.OK);
} catch (InterruptedException e) {
span.finish(SpanStatus.INTERNAL_ERROR);
throw new IllegalStateException("Nunca deveria acontecer enquanto dormindo.", e);
}
Colocamos o trecho acima no início do processamento do Serviço A.
Database no Sentry
Segundo a documentação do Sentry, sua integração JDBC creates a span for each JDBC statement executed. Transformar as invocações ao banco de dados em spans do Sentry é fantástico para identificarmos em que chamadas ao banco de dados estão nossos gargalos de desempenho.
Para isso, primeiro alteramos o build.gradle adicionando a seguinte dependência:
implementation 'io.sentry:sentry-jdbc:7.18.0'
Na sequência alteramos também o application.properties:
#spring.datasource.url=jdbc:postgresql://localhost:58432/sentry-lab?ApplicationName=service-b
#spring.datasource.driver-class-name=org.postgresql.Driver
spring.datasource.url=jdbc:p6spy:postgresql://localhost:58432/sentry-lab?ApplicationName=service-b
spring.datasource.driver-class-name=com.p6spy.engine.spy.P6SpyDriver
Por fim, para evitar a geração de arquivos de log localmente, criamos o arquivo src/main/resources/spy.properties:
modulelist=com.p6spy.engine.spy.P6SpyFactory
Isso foi feito seguindo basicamente a documentação do Sentry sobre a integração JDBC, mas com algumas pegadinhas: a versão do sentry-jdbc compatível com a versão do Spring Boot do projeto não era a 8.0.0. Para evitar os logs locais, a documentação sugere duas opções (criar spy.properties ou alterar application.properties), mas somente uma delas funcionou (spy.properties).
Integração com logs
No Sentry, os logs se vinculam aos erros capturados. Isso ocorre já por padrão. Para mostrar isso, criamos um registro de log logo no início da execução de cada uma das operações de nossos serviços, conforme segue:
import lombok.extern.log4j.Log4j2;
@RestController
@Log4j2
public class ServiceAController {
// ...
@GetMapping("/albuns/aleatorio")
public Album hello() {
log.info("Something quite interesting seemed to have happened here...");
Pela documentação e tutoriais na Internet, há uma ideia de que a dependência io.sentry:sentry-logback:7.18.0 traria mais detalhes ao breadcrumb que compõe o detalhamento de um erro no Sentry. Mas pelo menos para nosso caso, não observamos efeito aparente, então optamos por não utilizar essa dependência.
Resultados no Sentry
Visão de erros capturados
Abaixo temos a vissão de issues do Sentry:
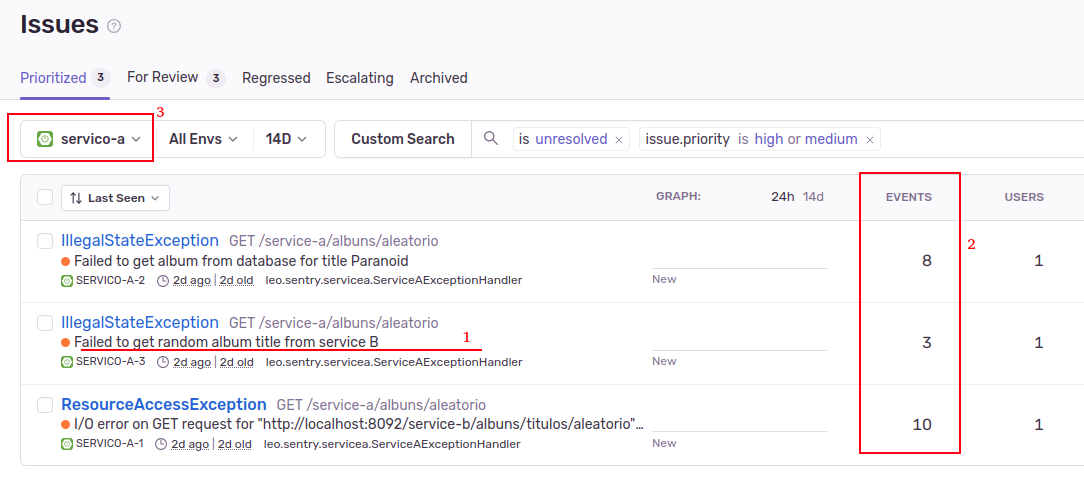
Nessa tela (Figura 2), podemos ver:
- Os diferentes erros ocorrendo em nosso sistema.
- O quantitativo desses erros. Além disso, ainda dá pra ver é se um determinado erro está afetando muitos usuários ou apenas alguns poucos. Essas questões são importantes para auxiliar na priorização do tratamento desses erros.
- Que é possível filtrar os erros por módulo (serviço); isso é importante pois ajuda cada equipe a focar em seus problemas.
Para cada ocorrência de cada erro, temos uma tela com os detalhes do erro:
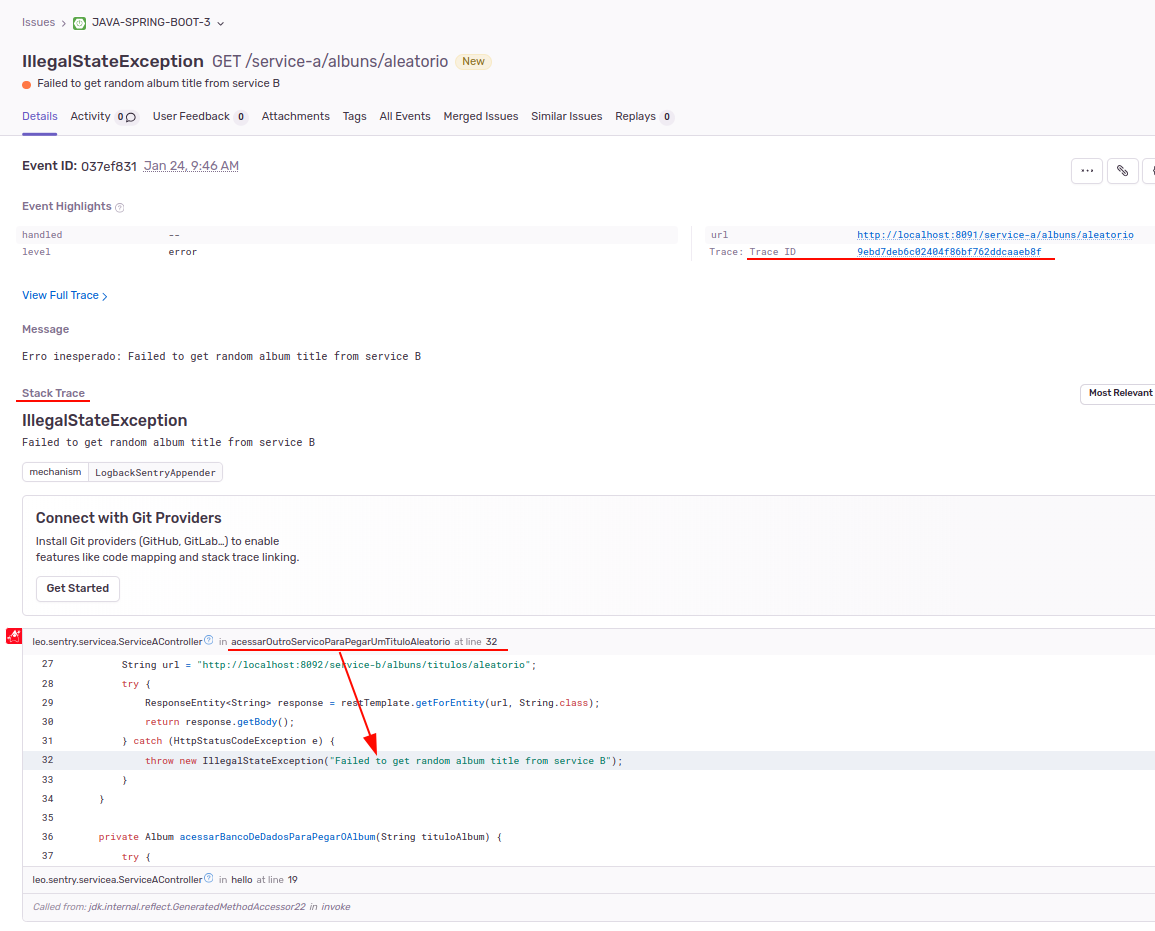
Nessa visão do erro (issue), podemos ver diversos detalhes, como a data-hora do erro, o trace ID da transação distribuída e o stack trace do erro. Esse stack trace inclusive é exibido de forma integrada ao código-fonte (o que não teríamos normalmente em um log)!
Nessa mesma visão temos ainda um breadcrumb que exibe os logs ocorridos durante a execução que gerou o erro:
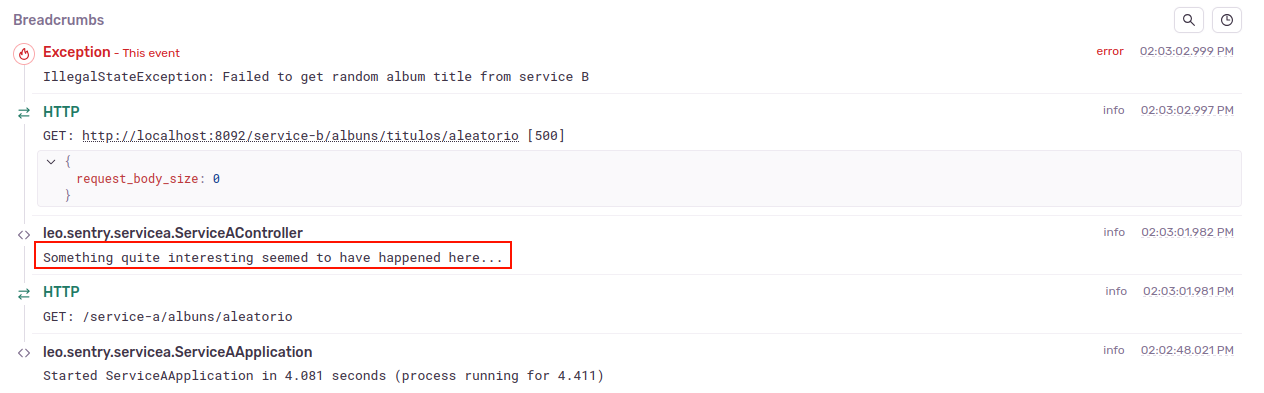
Uma observação: o erro está associado a um módulo, de forma que o stack trace e o breadcrumb farão menção apenas aos acontecimentos dentro do módulo. Ou seja, para um erro associado ao serviço A, o stack trace não mostrará as linhas de erro do serviço B e o breadcrumb não mostrará os logs registrados pelo serviço B.
Visão de rastro distribuído
E essa é a incrível visão de rastro distribuído que o Sentry nos fornece:

Nessa visão (Figura 5), vemos os spans que compõe o rastro, sendo que são exibidos os spans de todos os serviços envolvidos naquela transação distribuída (identificada por um trace ID). Além disso, observamos que:
- Podemos selecionar os diferentes spans que compõe o rastro.
- A interface exibe o erro associado àquele span.
- A interface exibe o módulo (serviço) em que o span selecionado foi executado.
- Vemos inclusive os spans personalizados.
- Temos o tempo de execução de cada span. No caso do span “dormindo”, que foi um span personalizado, temos o tempo de pouco mais de 1 segundo, o que era esperado já que nesse span executamos o comando
Thread.sleep(1000);. - E temos também os spans de acesso ao banco de dados, exibindo inclusive a consulta SQL realizada.
Encontrando um trace no Sentry pelo trace ID
Dado um trace ID (ex: eb30841f72144188abc3cea2592265db), podemos encontrar seu trace correspondente no Sentry utilizando o filtro trace:eb30841f72144188abc3cea2592265db na barra de busca de algumas telas, como a tela de issues e a de performance de uma transação. Supostamente deveria funcionar na tela de transações, mas não funcionou.
Um projeto por serviço vs um projeto para todos os serviços
Nesse tutorial, utilizamos a configuração de um projeto Sentry por serviço. Como vemos pelos resultados obtidos (Figuras 2 a 5), nessa opção temos a visão integrada do rastro distribuído. Ao mesmo tempo, é muito fácil observar apenas os erros de um determinado serviço. Além disso, na visão de rastro distribuído temos o esclarecimento sobre a que serviço se refere cada span. Ou seja, excelente.
Mas também experimentamos a estratégia de utilizar um único projeto Sentry para diferentes serviços. Contudo, essa estratégia apresentou inconvenientes e nenhuma vantagem particular (a não ser maior facilidade de configuração). Nessa opção, em alguns contextos não há forma prática de se filtrar itens por módulo ou se identificar o módulo associado a um item. Ou seja, numa situação de diferentes equipes cuidando de diferentes módulos, provavelmente haverá a dificuldade de “deixa eu ver aqui só as coisas da minha equipe”.
Portanto, recomendamos a configuração de um projeto Sentry por serviço (i.e., módulo do sistema).
Trace ID do Sentry nos logs e na mensagem de erro interno
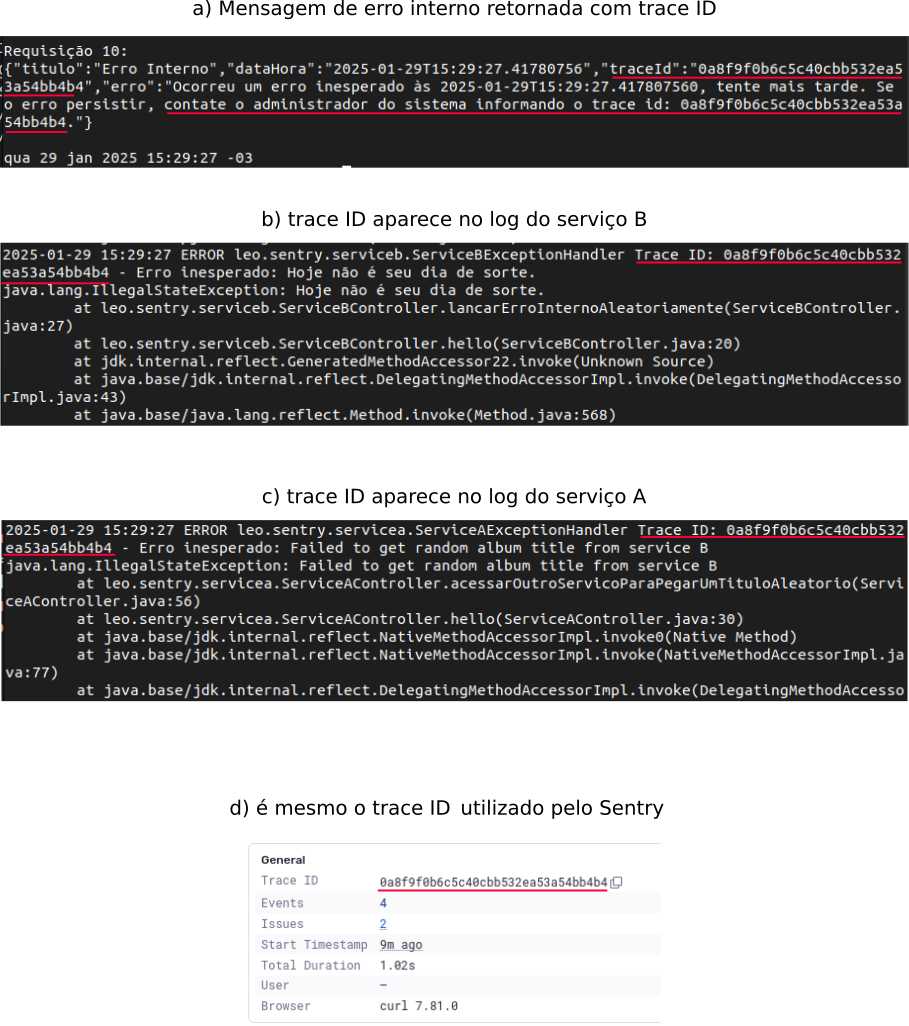
Quando uma requisição é feita a um “serviço de borda” de nosso sistema, a instrumentação do Sentry gera um trace ID para aquela transação distribuída. A partir desse ponto, esse trace ID é propagado automaticamente pelos serviços do sistema. Contudo, o uso desse trace ID é mais efetivo se fizermos duas coisas a mais: 1) imprimirmos esse trace ID em cada registro de log e 2) retornarmos esse trace ID nas mensagens de erro interno (assim acionamentos podem ser abertos com o cliente nos fornecendo o trace ID).
Para colocar o trace ID no log, primeiro capturamos o trace ID do Sentry e o colocamos à disposição do log no “contexto MDC”:
@Component
@Order(1)
public class TraceIdFilter implements Filter {
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain chain)
throws IOException, ServletException {
String traceId = Sentry.getSpan().getSpanContext().getTraceId().toString();
TraceIdManager.configurarTraceId(traceId);
chain.doFilter(servletRequest, servletResponse);
}
}
public class TraceIdManager {
private static final String MDC_KEY = "traceId";
public static void configurarTraceId(String traceId) {
if (StringUtils.isNotBlank(traceId)) {
MDC.put(MDC_KEY, traceId);
}
}
public static String getTraceId() {
return MDC.get(MDC_KEY);
}
}
Agora para que o trace ID apareça no log, temos que configurar o log no application.properties:
logging.pattern.console=%d{yyyy-MM-dd HH:mm:ss} %-5level %logger Trace ID: %X{traceId} - %msg%n
E para que o trace ID seja também retornado na mensagem de erro interno:
@Data
public class MensagemDeErroInterno {
private final String titulo = "Erro Interno";
private final LocalDateTime dataHora = LocalDateTime.now();
private final String traceId = TraceIdManager.getTraceId();
private final String erro = "Ocorreu um erro inesperado às " + dataHora
+ ", tente mais tarde. Se o erro persistir, contate o administrador do sistema informando o trace ID: "
+ traceId + ".";
}
Assim, quando um erro interno estoura no serviço B, vemos o trace ID na mensagem de erro interno que recebemos do Serviço A, assim como nos logs de ambos os serviços:
Preocupações com resiliência e desempenho
Considere o comando Sentry.captureException(e) no exception handler. Nesse momento, o cliente do Sentry (em nossa aplicação) envia um evento ao servidor do Sentry. O que ocorre se essa comunicação estiver lenta? Vai lerdear nossa aplicação? O que acontece se essa comunicação falhar? Eventos serão perdidos? Em suma, como o Sentry trata questões de desempenho e de resiliência?
Pois bem, o Sentry possui mecanismos para lidar com essas questões:
- Fila de Eventos: O Sentry utiliza uma fila de eventos (em memória) para armazenar temporariamente os eventos que não puderam ser enviados imediatamente. Se houver um problema de rede, os eventos serão armazenados na fila e enviados assim que a conexão for restabelecida.
- Timeouts e Performance: O Sentry é configurado para não bloquear a aplicação. Ele utiliza timeouts para garantir que a aplicação não seja significativamente desacelerada devido a problemas de comunicação com o servidor do Sentry.
- Cache: O SDK do Sentry armazena eventos em cache localmente no disco quando não é possível enviá-los imediatamente ao servidor Sentry, por exemplo, devido a problemas de conectividade de rede. Esses eventos em cache serão enviados assim que a conectividade for restabelecida. O uso do cache no Sentry é habilitado por padrão.
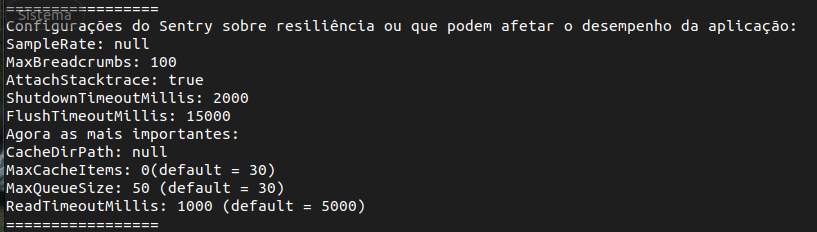
Existem algumas configurações do cliente do Sentry que influenciam o comportamento dos mecanismos listados acima. Achamos por bem customizar os seguintes (application.properties):
sentry.max-queue-size=50 # default 30
sentry.read-timeout-millis=1000 # default 5000
sentry.max-cache-items=0 # default 30
- Aumentar o tamanho da fila (
max-queue-size) aumenta a resiliência (i.e., favorece que eventos do Sentry não sejam perdidos), embora vá custar mais memória. - Diminuir o timeout de comunicação com o servidor Sentry (
read-timeout-millis) diminui a lentidão na aplicação em caso de impossibilidade na efetivação dessa comunicação (embora possa encher a fila com mais eventos e, assim, eventualmente contribuir para a perda de eventos). - Desabilitamos o uso do cache (
max-cache-items) considerando que a aplicação será executada em um contêiner Docker sem mapeamento de volume para o diretório desse cache (situação na qual o cache seria inútil, então melhor eliminar seu uso e assim diminuir o overhead de uso do Sentry).
A imagem abaixo mostra as configurações utilizadas:
Para imprimir essas propriedades:
public class SentryResilieConfiguration {
public static void print() {
System.out.println("=================");
System.out.println("Configurações do Sentry sobre resiliência ou que podem afetar o desempenho da aplicação:");
SentryOptions options = Sentry.getCurrentHub().getOptions();
System.out.println("SampleRate: " + options.getSampleRate());
System.out.println("MaxBreadcrumbs: " + options.getMaxBreadcrumbs());
System.out.println("AttachStacktrace: " + options.isAttachStacktrace());
System.out.println("ShutdownTimeoutMillis: " + options.getShutdownTimeoutMillis());
System.out.println("FlushTimeoutMillis: " + options.getFlushTimeoutMillis());
System.out.println("Agora as mais importantes:");
System.out.println("CacheDirPath: " + options.getCacheDirPath());
System.out.println("MaxCacheItems: " + options.getMaxCacheItems() + " (default = 30)");
System.out.println("MaxQueueSize: " + options.getMaxQueueSize() + " (default = 30)");
System.out.println("ReadTimeoutMillis: " + options.getReadTimeoutMillis() + " (default = 5000)");
System.out.println("=================");
}
}
@SpringBootApplication
public class ServiceBApplication {
@EventListener(ContextRefreshedEvent.class)
public void onApplicationEvent() {
SentryResilieConfiguration.print();
}
public static void main(String[] args) {
SpringApplication.run(ServiceBApplication.class, args);
}
}
Conclusões
Configuramos nossos serviços Spring Boot para trabalharem com o Sentry as-a-service (https://sentry.io), de forma que conseguimos:
- identificar os erros da aplicação no Sentry,
- atrelar o código-fonte ao stack trace,
- ver os registros de log no contexto de cada erro,
- ter belas visualizações de rastro distribuído,
- criar spans personalizados nesses traces,
- transformar os acessos ao banco de dados em spans no Sentry,
- mostrar o trace ID gerado pelo Sentry em nossas mensagens de log,
- retornar esse mesmo trace ID em nossas mensagens de erro interno e
- configurar propriedades que reforçam os aspectos de resiliência e desempenho da comunicação com o servidor do Sentry.
Experimentamos a configuração de um único projeto Sentry para todos os módulos (serviços) do sistema e a configuração de um projeto para cada módulo. Concluímos que a configuração de um projeto por módulo é mais adequada: fica fácil filtrar os erros de um dado módulo e sem perder a visão integrada do rastro distribuído.
Uma ressalva: o Sentry não é talhado para servir de auditoria das requisições. Embora parece ser possível contornar, a princípio não temos no Sentry o corpo da requisição e o corpo de resposta de cada invocação. Além disso, a recomendação para produção é que não se guarde o rastro de todas as invocações (inadequado para uma auditoria), o que também nos leva ao próximo ponto.
Questões em aberto
Pode ser impressão, mas parece que o Sentry é mais reconhecido por ser uma ferramenta para a análise dos erros (como dissemos, a agregação quantitativa de erros que o Sentry faz é bem valiosa). Contudo, seu uso como ferramenta de tracing parece um tanto quanto negligenciado pela comunidade.
O próprio Sentry indica que a propriedade sentry.traces-sample-rate não deve valer 1.0 em produção. Ou seja, em produção não teríamos o rastro distribuído de todas as execuções do sistema (embora talvez tenhamos todos os rastros das execuções envolvidas em erros). Me pergunto se isso seria suficiente em produção para dar conta das necessárias análises a serem realizadas em caso de reclamação de lentidão no sistema. Talvez um contorno seria capturar todos os rastros por apenas um pequeno período de tempo em determinadas situações.
Ainda não utilizei a funcionalidade de rastro distribuído do Sentry pra valer em produção. Portanto, não tenho respostas para as inquietudes acima registradas. Porém, sei que quando falamos em rastro distribuído, nomes como Jaeger e Open Zipkin parecem ser mais consolidados. E há ainda, mais recentemente, o Grafana Tempo, que parece ser bem promissor por melhor explicitar suas preocupações com desempenho e escalabilidade para a captura de todos os rastros do sistema.
PS: outras funcionalidades do Sentry
Como executamos os serviços de demonstração apenas em localhost, não chegamos a explorar algumas funcionalidades do Sentry que são mais difíceis de avaliar nesse contexto. Mas vale citar duas capacidades importantes que o Sentry oferece:
- No
application.propertiesé possível configurar a propriedadesentry.environment(exemplo de valor:production). Assim, passa a ser possível filtrar os eventos do Sentry por ambiente. - No
application.propertiesé possível configurar a propriedadesentry.release, sendo uma das estratégias recomendadas preencher essa propriedade com o hash do commit que está sendo publicado (exemplo:da39a3ee5e6b4b0d3255bfef95601890afd80709). Assim podemos ter uma ideia de qual versão do código pode ter causado, por exemplo, um aumento em determinado tipo de erro.