em
Um argumento contra a transcrição automática em pesquisas de Grounded Theory que se baseiam em entrevistas
Pesquisas que seguem a metodologia da Grounded Thoery (“Teoria Fundamentada em Dados”) se baseiam na análise de um conjunto de dados qualitativos. Nas pesquisas de engenharia de software, tipicamente esses dados são transcrições de entrevistas conduzidas por pesquisadores com profissionais da área. Em geral muitas entrevistas devem ser feitas; não há um número definido, mas na prática algo maior que 30. Além disso as entrevistas podem ser longas… pelo menos meia-hora, mas em geral sendo cerca de uma hora.
Para analisar as entrevistas, é comum que os pesquisadores façam a transcrição das entrevistas. E, num primeiro momento, parece muito conveniente realizar a transcrição automática com a ajuda de alguma boa ferramenta. Contudo, há pelo menos um argumento contra isso, e vou apresentá-lo aqui.
O núcleo da prática da Grounded Theory, no contexto descrito, consiste na elaboração de codes (conceitos abstratos) a partir de trechos das entrevistas e na comparação constante desses codes, de forma que eles evoluam ao longo da análise (i.e., sejam criados, alterados, eliminados e mesclados).
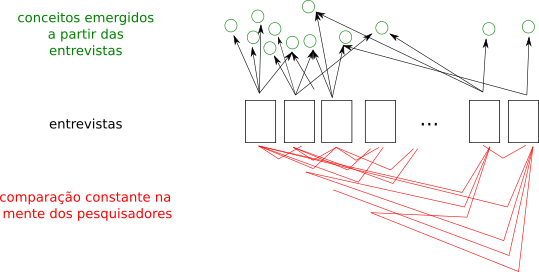
Para uma prática mais eficaz dessa comparação constante defendo que os pesquisadores devem ter de cor (i.e., “no coração”) os fatos e alegações narradas em cada entrevista. Mas dado à grande quantidade de entrevistas, isso pode ser difícil. Como reter na mente todas essas entrevistas? Em geral as primeiras são mais marcantes e as últimas estão na memória por serem mais recente, mas talvez as entrevistas intermediárias corram o risco de serem mais negligenciadas.
Pois bem, por mais árduo (i.e., demorado e tedioso) que seja, advogo que a transcrição manual (transcrever o texto enquanto se houve a gravação da entrevista) é a forma que pesquisadores tem de fortalecer essa memória sobre o que vivenciaram e assim alavancarem suas capacidades analíticas durante o processo de comparação constante.
PS: olhando a Figura 1, em princípio, poderíamos dizer que um pesquisador deve comparar a entrevista sendo analisada com os codes já estabelecidos, e não diretamente com o conteúdo de entrevistas anteriores. Mas acredito que, na prática, é inevitável que a pesquisadora pense diretamente sobre as entrevistas, ou seja, sua própria experiência viva.
Excelente complemento do professor Breno de França (Unicamp)
Claro, a transcrição manual torna os pesquisadores mais íntimos dos dados coletados, ou seja, o que alguns pesquisadores chamam de “estar familiarizado com seus dados”. No entanto, a transcrição manual não é a única maneira de conseguir isso. No meu grupo, usamos transcrição automatizada, mas depois ouvimos a entrevista inteira e revisamos a transcrição. Dessa forma, você ainda está familiarizado com os dados, mas com menos digitação!
Adendo: Recentemente, ouvi (de várias fontes) a ideia de coding baseado em LLM. Isso faria os pesquisadores perderem o contato com os dados e, consequentemente, a compreensão! Então, como pesquisador qualitativo, sou fortemente contra essa prática…
Obrigado por compartilhar suas ideias prof. Breno!