em
Headers HTTP para rastro distribuído (observabilidade) - Parte 4: Listagens de headers HTTP na web
Esta série de posts investiga os headers HTTP usados para apoiar o rastro distribuído (tracing), que é um dos pilares da observabilidade (composta também por logs e métricas). Embora foquemos na investigação sobre esses headers, estes posts servem também como uma introdução sobre rastro distribuído e como apresentação de algumas alternativas tecnológicas para sua implementação. Como valor agregado extra, destrinchamos e interpretamos a documentação de algumas dessas alternativas; documentação essa, francamente, não tão fácil de assimilar. Neste post examinamos algumas listagens de headers HTTP conhecidos e tentamos chegar a um veredito sobre que headers utilizar.
Contextualizando
O rastro distribuído (tracing) diz respeito aos processos, padrões e ferramentas que possibilitam que a equipe de desenvolvimento compreenda as requisições feitas a partir da invocação a um determinado serviço, dando a possibilidade de correlacionar erros ocorridos em diferentes serviços. Exemplo: entender que o erro interno no serviço A foi devido a um determinado problema no serviço B (sendo o serviço B invocado pelo serviço A).
Na solução caseira de rastro distribuído de minha equipe, usamos alguns headers na invocação de um serviço para o outro: o X-Request-ID, que identifica a transação distribuída em execução; o CLIENT_APPLICATION_NAME, que transporta o nome do serviço cliente que realizou a invocação; e o CLIENT_CHAIN, com a lista dos nomes dos serviços que fizeram parte da cadeia de invocações até o momento.
A figura abaixo resume nosso esquema de headers para o rastro distribuído entre nossos serviços.
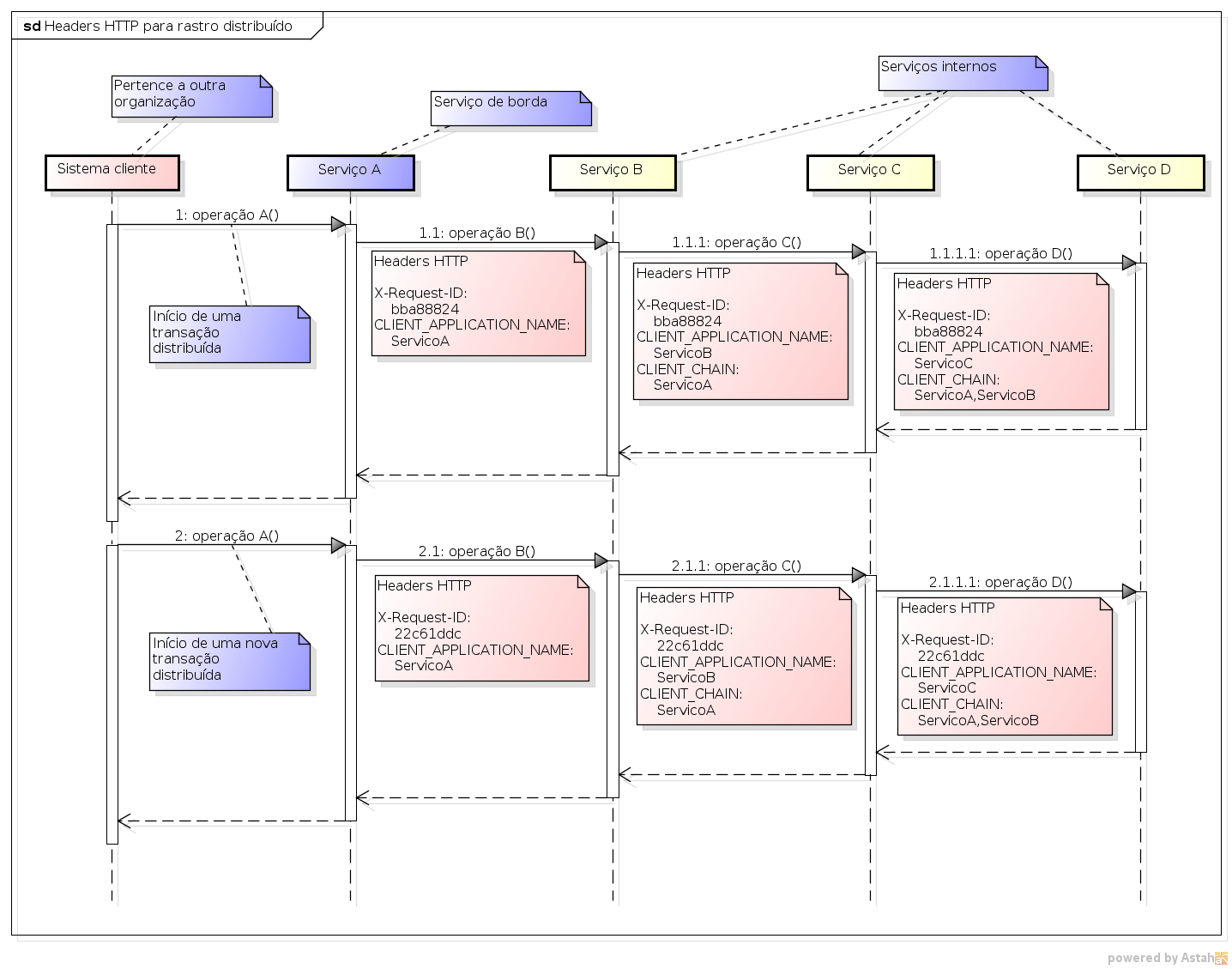
E aí surge a indagação: o que fizemos seria muito diferente do preconizado pelas soluções de mercado? Diante disso, nossa questão é: poderíamos ter uma solução caseira utilizando headers de apoio a rastro distribuído que fossem compatíveis com soluções de mercado? Ou seja, não estou muito interessado em adotar uma biblioteca ou framework específico, mas acharia interessante que os headers utilizados na solução caseira fossem padronizados. Por isso é bem interessante observar listagens de headers HTTP já padronizados, que é o que faremos agora.
Ah, se essa recontextualização não lhe foi o suficiente, considere rever as seções iniciais de nosso primeiro post da série (i.e., as seções antes de iniciarmos a descrição sobre o Spring Cloud Sleuth).
Listagens de headers HTTP
Procurando na Internet listagens de headers HTTP, encontramos alguns headers de alguma forma relacionados ao rastro distribuído.
http.dev
Essa página misteriosa [1] (mantida por não sabemos que organização) esclarece sobre o X-Request-ID:
The HTTP X-Request-ID request header is an optional and unofficial HTTP header, used to trace individual HTTP requests from the client to the server and back again. It allows the client and server to correlate each HTTP request.
Ou seja, a princípio não seria exatamente um header para carregar um identificar de todo o rastro distribuído, mas mais para correlacionar um par de requisições que constituem um pedido e uma resposta.
Wikipedia
A Wikipedia [2] reforça que X-Request-ID é um “common non-standard” header e diz que ele:
Correlates HTTP requests between a client and server. Superseded by the traceparent header.
Ou seja, a página sugere que o X-Request-ID não deve ser mais usado em favor do header traceparent especificado pela W3C [3]. Conforme vimos no primeiro post da série, o header traceparent é composto pelos campos version, trace-id, parent-id e trace-flags, dos quais os mais interessantes são os trace-id (identifica o rastro de execução da transação distribuída) e o parent-id (identifica a invocação; de acordo com o documento, equivaleria ao span-id). E lembrando que essa padronização proposta pela W3C é suportada pelo Spring Sleuth.
Ainda segundo a Wikipedia, outros headers equivalentes ao X-Request-ID são o X-Correlation-ID e o Correlation-ID.
Mozilla MDN Web Docs
Na lista de headers da Mozilla [4] aparentemente não temos nenhum header de correlação de rastro distribuído.
Conclusão
Em nossa solução caseira utilizamos o header X-Request-ID para identificar o rastro de execução de uma transação distribuída. Mas parece que a escolha não foi a melhor, pois um “request ID” identifica uma requisição (ou um par de requisições no nível tecnológico que na verdade formam um par pedido/resposta no nível do negócio). No caso, queremos um ID que identifique um conjunto de requisições (todas pertencentes a um mesmo rastro de execução de uma transação distribuída). Para esse propósito, o termo mais comumente utilizado nas ferramentas e padrões estudados (Sleuth, B3, W3C, OpenTracing, Tempo) seria “trace id”. Utilizando o case tipicamente utilizado para headers HTTP, teríamos o header Trace-ID.
Outro nome potencialmente equivalente ao Trace-ID é o Correlation-ID. Esse termo não foi encontrado em nosso estudo, exceto apenas pelas listagens de headers conhecidos sobre o assunto. Contudo, o termo “correlation” já é usado há um bom tempo; é, por exemplo, descrito como um padrão no famoso livro Enterprise Integration Patterns [5] (embora num contexto mais simples, o de correlacionar um resposta assíncrona para sua requisição correspondente). Também já vi o termo “correlation ID” na formação Kafka da Alura [6] (curso ótimo, por sinal).
Quanto ao header CLIENT_APPLICATION_NAME, o mais próximo que encontramos aparentemente seriam os campos parent-id do header traceparent da recomendação da W3C e o header ParentSpanId na especificação b3. Contudo, esses campos não carregam a identificação do cliente (ou “parent”), mas sim a identificação de alguma requisição. Então, embora Parent-ID possa parecer uma opção simpática e com termos alinhados aos padrões, pode ser confuso para quem já conhece esses padrões, já que queremos simplesmente saber quem é o invocador da requisição. Com isso, no momento proporia apenas a adaptação do nome CLIENT_APPLICATION_NAME para Client-Application-Name.
Quanto ao CLIENT_CHAIN, não encontramos nada equivalente. Mas no mínimo seria interessante adequar o case. Teríamos então Client-Chain.
Baseado nessas considerações, no momento parece então que a seguinte renomeação de nossos headers seria interessante:
X-Request-IDviraTrace-ID.CLIENT_APPLICATION_NAMEviraClient-Application-Name.CLIENT_CHAINviraClient-Chain.
E você, como fez? Ou o que faria? Me conta lá no LinkedIn! :)
Referências
[1] https://http.dev/x-request-id
[2] https://en.wikipedia.org/wiki/List_of_HTTP_header_fields
[3] Trace Context, W3C Recommendation (2021): https://www.w3.org/TR/trace-context/#trace-context-http-headers-format
[4] https://developer.mozilla.org/pt-BR/docs/Web/HTTP/Headers
[5] Enterprise Integration Patterns - Messaging Patterns - Correlation Identifier
[6] Formação Mensageria com Apache Kafka da Alura. https://www.alura.com.br/formacao-kafka