
Trabalho de Conclusão de Curso do Bacharelado em Ciências da Computação do IME trouxe melhorias de desempenho ao programa de controle de versões livre e de código aberto mais popular entre os desenvolvedores no mundo.
O programa livre e de código aberto Git registra as modificações feitas a um projeto ao longo do tempo, permitindo que se possa recuperar o que foi feito em versões passadas. Armazenando, dentre outras informações, os autores e datas das modificações, o software possibilita que equipes (potencialmente grandes e/ou distribuídas) de desenvolvedores mantenham saudável a elaboração colaborativa de código. E vale ressaltar que seu uso não é exclusivo para versionamento de código fonte, podendo gerenciar quaisquer tipos de arquivos.
O software, criado em 2005 por ninguém menos que Linus Torvalds, é usado atualmente para versionar inúmeros projetos de variadas características e tamanhos. Desde o próprio kernel Linux – cujo repositório contém aproximadamente 1.0GB de arquivos e 1.4GB de objetos (i.e. dados históricos armazenados pelo Git) – até repositórios como o do Windows – com 300GB de arquivos e 100GB de objetos. Dada a ampla gama de usuários, com as mais diversas demandas de armazenamento, fica claro porque os desenvolvedores do Git prezam tanto por desempenho e escalabilidade. Com essa mesma motivação, o trabalho de Matheus Tavares Bernardino, aluno do Instituto de Matemática e Estatística da Universidade de São Paulo, buscou entender e solucionar a baixa performance do comando git-grep em revisões históricas.
De acordo com Matheus, “O comando git-grep, responsável por buscar padrões textuais em arquivos monitorados pelo Git, executava com boa performance em buscas no diretório de trabalho (i.e. na versão atual do projeto). Porém, nas buscas em versões antigas, o comando tomava muito mais tempo, mesmo quando paralelizando o trabalho em múltiplas threads. O objetivo do projeto foi entender a razão desta tão proeminente diferença e, com melhorias na paralelização, permitir que o git-grep tivesse um bom desempenho paralelo também em versões antigas.”
Antes de planejar a execução do projeto em sí, foi essencial estudar as tarefas de compilar, testar e submeter mudanças de código ao software de versionamento. Desta forma, o pesquisador pôde adquirir familiaridade com o fluxo de contribuições do Git e com as interações da comunidade. Sendo essa comunidade composta por estudantes, pesquisadores, funcionários de empresas como Google e Microsoft, e demais contribuidores espalhados pelo mundo, trabalhando colaborativamente para o aprimoramento contínuo do sistema.
Parte do trabalho foi financiado pelo programa global Google Summer of Code, que seleciona estudantes ao redor do mundo para realizar projetos de desenvolvimento em sistemas de código aberto, como o Git. Sob a valiosa orientação de membros da comunidade de desenvolvedores do Git e a mentoria do professor Alfredo Goldman, do IME/USP, Matheus estudou os códigos do software à procura de trechos com alto tempo de execução e que pudessem ser paralelizados.
Nas palavras do seu mentor, o professor Alfredo Goldman “O trabalho realizado foi excepcional, pois conseguiu unir de forma clara várias contribuições. Primeiro, foi um trabalho onde foi necessário entender o contexto dos desenvolvedores do Git para falar a língua deles, conseguindo uma aceitação rápida na comunidade. Segundo, foram usadas técnicas de ponta para conseguir melhorar a eficiência de um código em produção. Finalmente, escrever parte de um código que é usado por centenas de milhões de pessoas.”
Por meio de aprimoramentos na paralelização do código, o estudante conseguiu acelerar em mais de 3 vezes a execução do comando git-grep em versões históricas, o que beneficia o trabalho de desenvolvedores em vários segmentos. “Realizamos diversos testes para determinar em que sessões do código havia maior gasto de tempo.” – relatou Matheus – “Notamos, então, que em alguns casos a descompressão de objetos do Git chegava a representar mais de um terço do tempo de execução total do comando. Além disso, o código que a envolvia não era seguro para execução paralela, e portanto, seu custo computacional não podia ser dividido entre múltiplas threads. Com aprimoramentos tanto no código de leitura de objetos como no paralelismo do git-grep, conseguimos que a descompressão de objetos fosse realizada de forma paralela e segura. Assim, alcançamos uma aceleração superior a 3x, com 8 threads em um processador de 4 núcleos e hyper-threading. Neste processo, também foram corrigidas algumas condições de corrida no código do git-grep, e um bug relativo à busca em submódulos.”
As melhorias propostas no trabalho já foram incorporadas à base de código do Git, podendo ser encontradas na versão 2.26.0 do software, que foi lançada no final de março deste ano. O trabalho trouxe melhorias reais e significativas para uma ferramenta largamente utilizada, livre e de código aberto. Trata-se de uma contribuição de grande impacto, que parte da universidade pública brasileira para o universo de desenvolvedores e gestores ávidos por velocidade ao redor do mundo.
Gráficos comparando a performance do git-grep antes e depois das mudanças propostas no projeto.
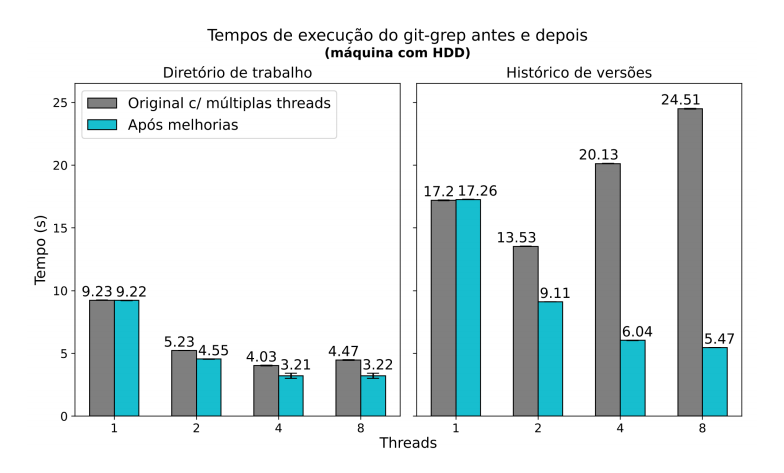
Cada gráfico traz os resultados em uma máquina diferente: a primeira com HDD e a segunda com SSD. Os valores, apresentados com intervalos de confiança de 95%, correspondem aos tempos de execução do comando, ao buscar o padrão “(static|extern) (int|double) *”' nos arquivos do projeto Chromium. À esquerda, estão as buscas no diretório de trabalho e à direita, as buscas no histórico.
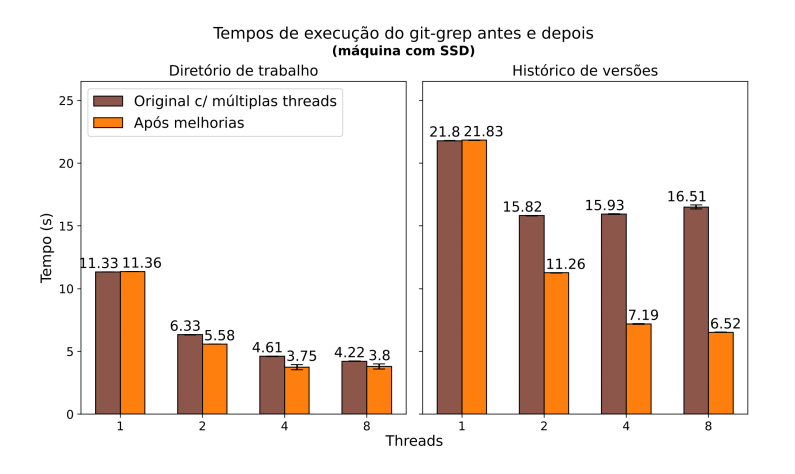
Note que o código original forçava a execução em uma única thread para buscas no histórico (pela queda de performance, em alguns casos, ao utilizar múltiplas threads). Mas esta limitação foi removida para comparação. Os resultados mostram um aumento de performance de até 3.3x em buscas históricas – com relação ao código original em uma única thread – e quase 5x – ao permitir múltiplas threads no código original. Também observamos uma melhoria de 1.4x em buscas no diretório de trabalho.
O trabalho “Improving Parallelism in git-grep” de Matheus Tavares Bernardino pode ser lido clicando aqui
Texto Edina Arouca/ Matheus Bernardino
- Data
- 10 de junho de 2020