Borboleta: A Mobile Telehealth System
An Open Source Project - Mobile Telehealth Services for all
Banco de Dados Evolutivos
A modelagem evolutiva de bancos de dados é necessária devido às frequentes mudanças de requisitos das aplicações. O desafio é ainda maior quando o banco de dados tem que atender simultaneamente a várias aplicações. A solução atual para evolução utiliza refatorações e define um período de transição, durante o qual tanto o esquema antigo quanto o novo coexistem e os dados são replicados por meio de um processo síncrono que apresenta várias dificuldades, como a interferência no funcionamento normal das aplicações. Para minimizar essas dificuldades, propomos um processo assíncrono para manter atualizados esses esquemas e desenvolvemos uma ferramenta que implementa esse processo.
A figura abaixo mostra a refatoração Dividir tabela que será usada para explicar o processo assíncrono de replicação de dados em uma
refatoração:
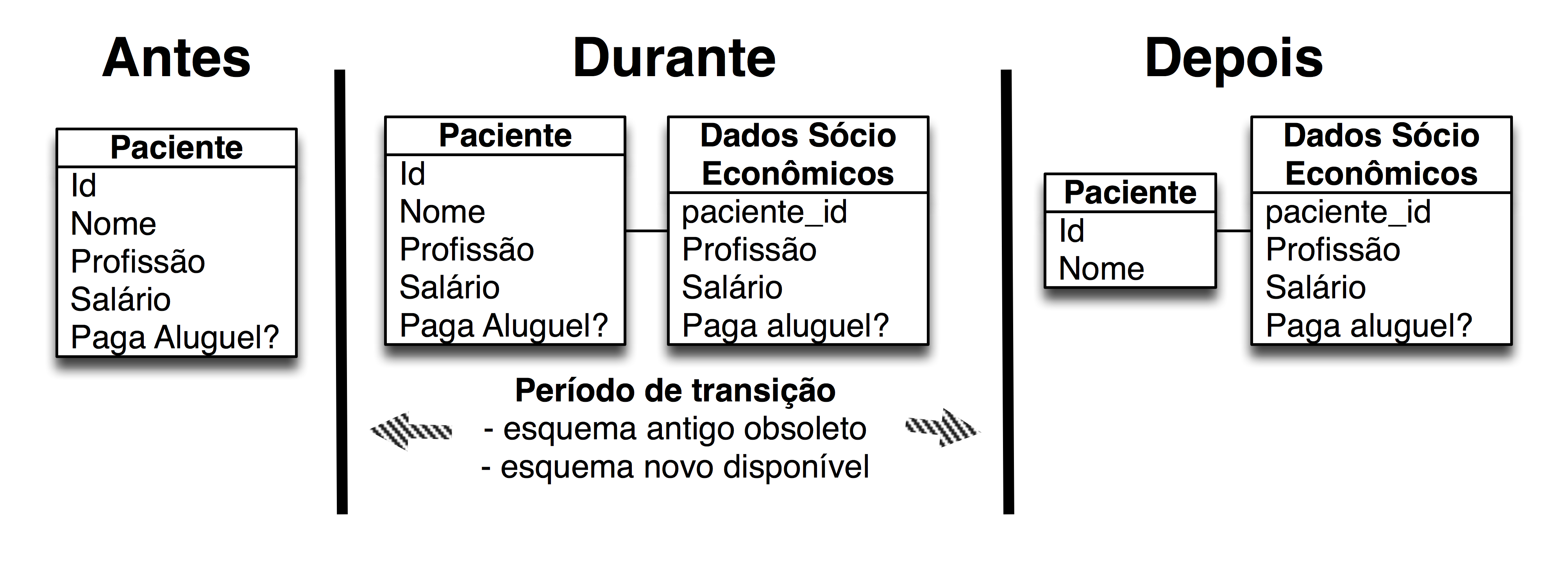
Considerando um contexto de modelagem evolutiva, temos uma tabela de pacientes que contém todos os atributos que gostaríamos de capturar no momento do cadastro: nome, profissão, salário e um indicador de que se ele paga ou não aluguel. Antes de começar uma iteração, percebemos que seria apropriado agrupar os dados sócio-econômicos em uma tabela separada. A partir dessa constatação, decidimos fazer a refatoração Dividir tabela. A tabela Paciente será dividida em duas: a própria tabela Paciente e a nova tabela Dados Sócio-Econômicos. Durante o período de transição, mantemos os atributos que originaram a tabela de dados sócio-econômicos na tabela de pacientes.
Para manter os esquemas novo e antigo atualizados, durante o período de transição, definimos o processo assíncrono de replicação de dados em três etapas:
A ferramenta Database Evolution Manager implementa essas três etapas e permite, até o momento, realizar as seguintes refatorações: